



Some new sites get indexed in Google within hours, and others—never. Moreover, some old websites can drop out of the index even if they were ranking in high positions for a while. What if you’re not seeing your site in Google search? Can Google Ads Management Services help?
There may be plenty of reasons for it.

How to quickly find and fix the problem? Just get a website audit report using SE Ranking, and all the main technical drawbacks damaging your site’s discoverability will be revealed. Let’s consider five common SEO headaches you may face and find out where they stem from.
1. Your Site Hasn’t Been Indexed Yet
Google only shows the websites that have made it to its index in the search results. Let’s look at several issues that may prevent or delay the indexation of your new pages or the entire website.
Your Website Is Absolutely New
If the content of a newly published website meets Google’s indexing requirements, the time it takes to index it will depend on how easily crawlers can find it. To help them, you should create a Google Search Console account and then verify your site and submit your XML sitemap through it.
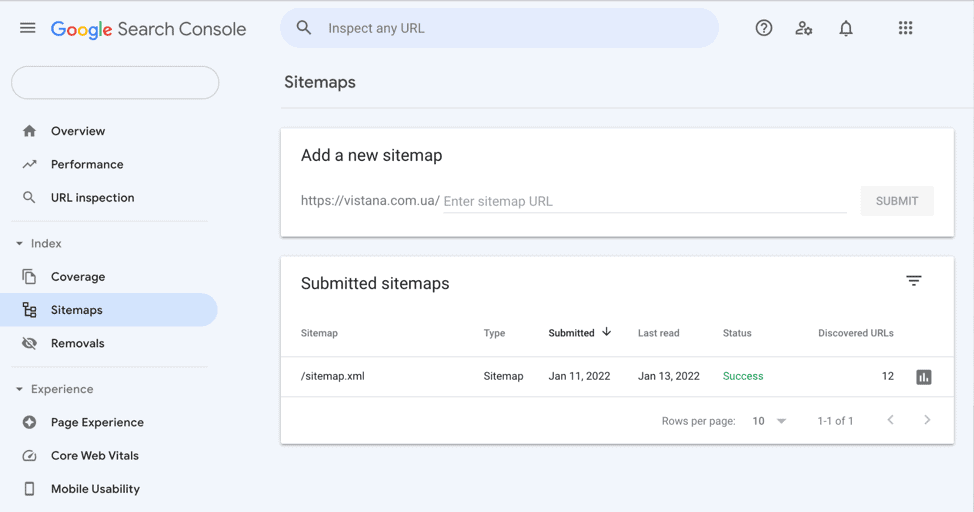

Your XML sitemap should reside in the root folder of your site and be available at a URL similar to domain.com/sitemap.xml. It can be automatically generated by WordPress or an SEO plugin that you use. If you want to have more control over what’s inside your sitemap.xml file, create it using SE Ranking’s Website Audit and upload it to your site.
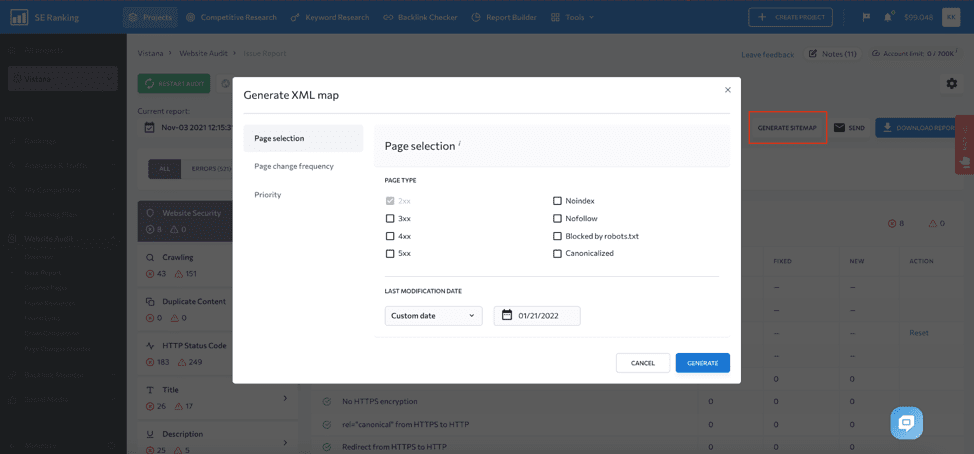

When your website gets large, you can check the Issue Report to stay on top of any problems that may harm your XML sitemap, such as when your XML sitemap becomes too large, non-canonical pages and pages blocked from indexing get listed in it, or if the link to the sitemap is missing from the robots.txt file.
Your Site Code Contains Noindex Directives
There are cases when submitting your XML sitemap to Google won’t solve issues with indexing. You might have noindex directives added in robots meta tags in the HTML code (<meta name=”robots” content=”noindex”/>) or in the X-Robots-Tag in the HTTP Header (X-Robots-Tag: noindex).
Whereas the robot’s meta tag blocks every page from crawlers, the X-Robots-Tag can be applied sitewide. A particular URL may contain noindex directives in both tags, which is overkill and should be fixed.
Your developer or webmaster might have added the tags to prevent empty pages from indexing while the website was under construction or maintenance and hasn’t removed them yet. You’ll get a list of pages blocked with noindex directives by running an SEO audit with SE Ranking.
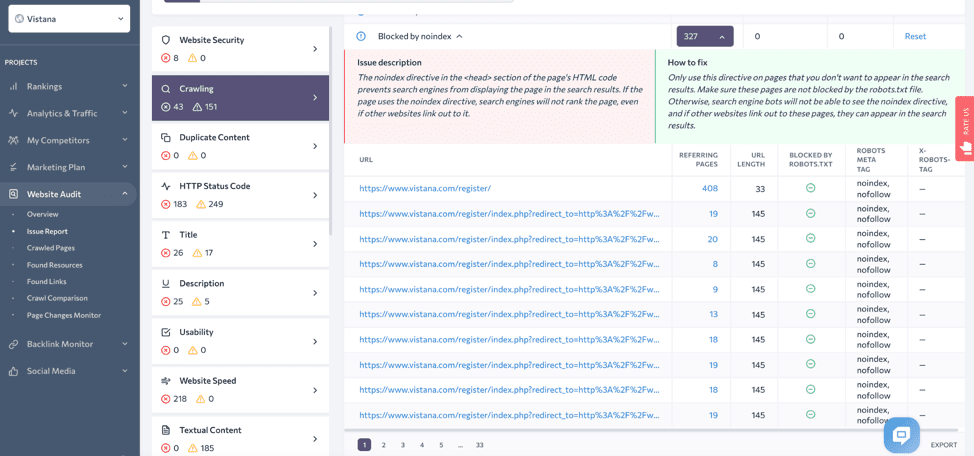

You should remove the noindex directives from all the pages you want to see in search results to fix the issue. It can be as easy as removing a tick from the Discourage Search Engines From Indexing checkbox in your Search Engine Visibility settings in WordPress. But in some cases, it may require editing configuration files of your site’s web server.
You Block Google Bots in the Robots.txt File
It may happen that your website is indexed, but not to the full extent. This can make your new pages too long to index if you have crawling issues on the website. Look at the Blocked by robots.txt section of the Issue Report to exclude the possibility that you are restricting the wrong pages from crawling.
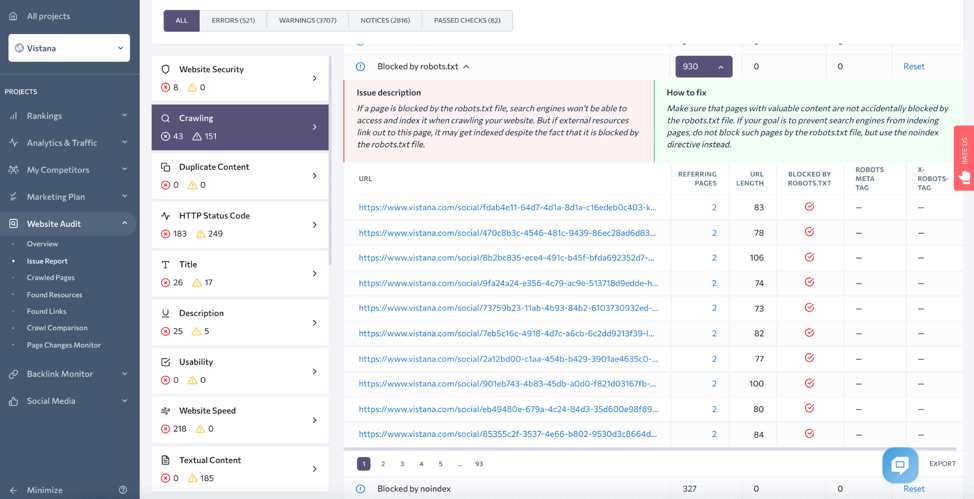

Sometimes the whole website can be blocked from crawling with a restricting directive that reads “Disallow: /” where the slash means all folders of your site.
2. Poor Site Structure and Internal Linking
Sometimes new pages don’t get indexed for very long. This happens if Google bots can’t find enough ways to reach the content that’s still due to be crawled. To fix this issue, you should improve your internal linking structure.
Think about how easy it is for crawlers to reach the new pages from the homepage. If your pages appear more than 4 clicks away from it, they’re sitting too deep in the site’s hierarchy. Crawlers may spend the whole crawling budget before discovering these pages.
It’s even worse if very few links or even no links are pointing to your new pages. Crawlers may not find these pages. When they finally do, they may consider the pages unimportant because the number of incoming internal links indicates the relative importance of a page.
With the help of the technical SEO audit, you can detect orphaned pages. They’ll be listed under the No Inbound Links and the One Inbound Link reports.
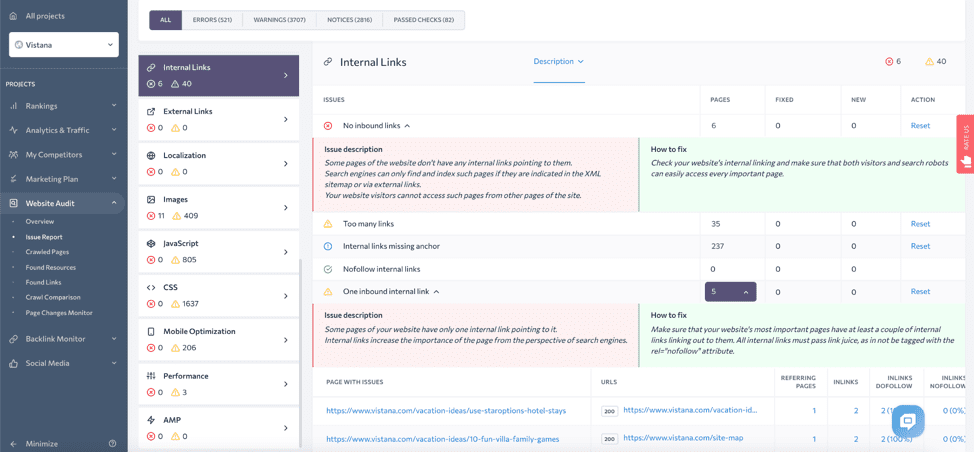

You should also pay attention to the Nofollow Internal Links report. It will indicate if you are blocking crawlers from following links between pages on your site by adding the rel= “nofollow” attribute to the <a> tags. This attribute helps to keep pages out of search results if paired with a noindex directive on the destination page. You might want to add it to the links pointing to user login pages, but not your product or blog pages.
3. Your Site Has HTTP Errors
Your site’s search performance can be affected by errors on your site and server. When requesting access to a page, the first thing that Googlebot receives is an HTTP status code. It then decides what to do with the page:
- Pages with 2XX codes enter Google’s indexing pipeline.
- Pages returning 3XX codes won’t be processed, and moreover, they’ll be considered erratic if the crawler doesn’t find the destination page in ten hops.
- Pages with 4XX codes aren’t considered for indexing by default or can drop out of the index if they’ve been indexed before.
- The 5XX server error status codes cause Googlebot to slow down your site crawling. Pages that continuously return 5XX codes will drop out of the index.
SE Ranking’s Website Audit can detect up to 30 issues related to the HTTP statuses flagging different errors. Look through the HTTP Status Code and the Redirect sections in the Issue Report to see if any of your pages are affected.
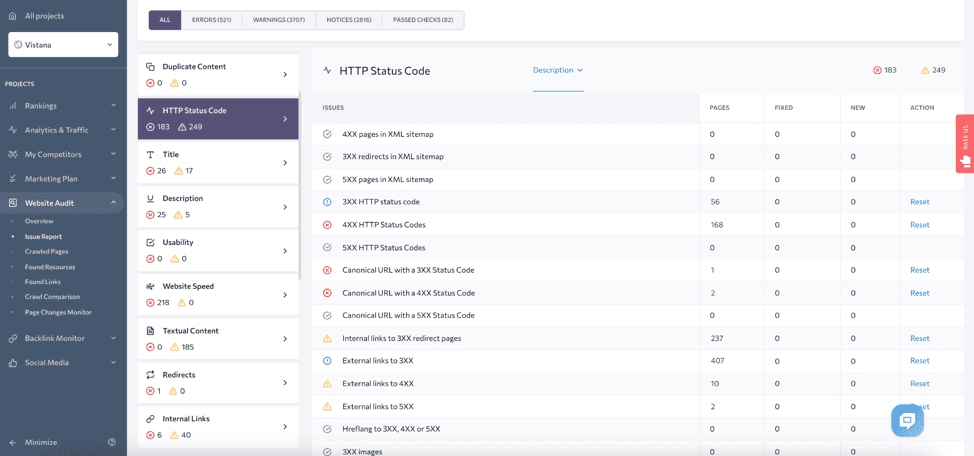
You should be able to find and fix website and server errors quickly. If Google encounters them regularly, it reduces the crawling frequency for your site, which creates impediments for indexing your future content. To stay on top of your site’s health, you can schedule regular site audits and make checking them part of your SEO routine.
4. You Have Duplicate or Thin Content
Several issues related to on-page content may prevent your URLs from showing up in Google search. For various reasons, Google may not consider your content sufficient, original, or relevant enough to index it or rank it high.
Duplicate Content
Your website may contain more content than Google is willing or able to crawl. Some types of overhead pages may waste your site’s crawl budget, such as internal search results, URLs containing user session IDs and UTMs, or same product pages within different categories.
Some of your site features, like faceted navigation, can create ‘crawler traps’. By being caught in such a trap, bots start crawling an endless number of parameterized URLs with similar content instead of processing important pages.
There are several measures you can take to distribute your site’s crawl budget wisely:
- Block overhead URLs from crawlers by adding disallow directives to your robots.txt file.
- At the same time, your sitemap will show search bots what you want them to crawl.
- Consolidate duplicate pages by adding the <a> tags with rel=canonical attributes pointing to the main version of the page that should be indexed.
The pages with duplicate content will be flagged in the Duplicate Content section of the Issue Report.
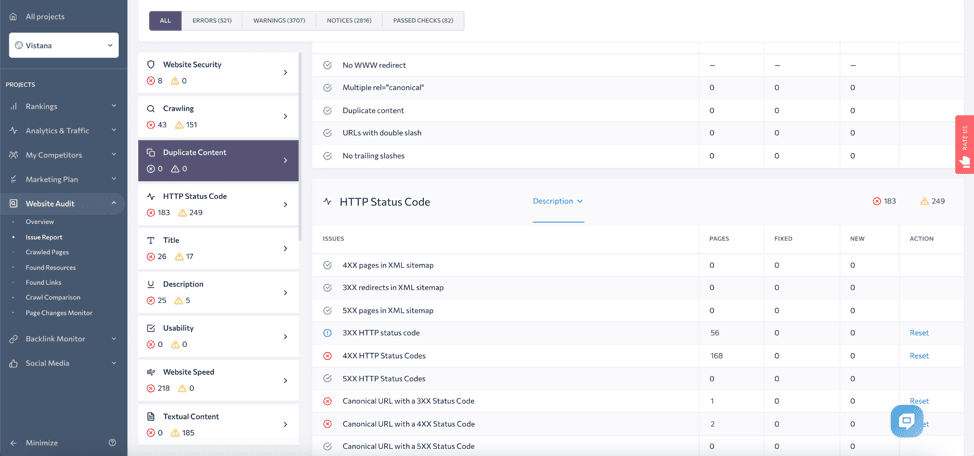
Thin Content
Another reason Google may ignore your pages is that they consider your content insufficient for indexing. If any of your pages is almost empty or simply doesn’t provide the expected information, it may fall in the category of thin content.
Check the Textual Content section of the Issue Report to see if any of your pages have less than 250 words. Yet, keep in mind that a low word count is just one of the signs of insufficient content. The main criterion is the value that content brings to the user.
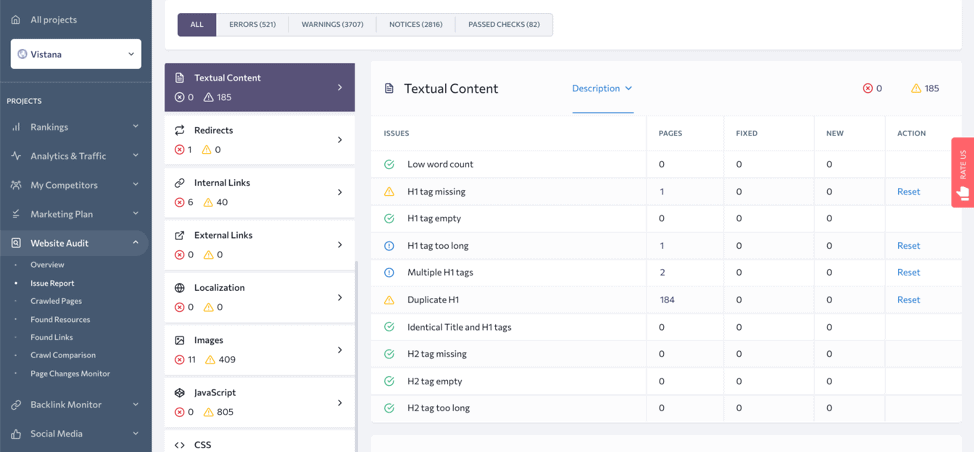
Messy URLs and Metadata
In the Textual Content section, you can check some other issues that might affect Google’s perception of your pages’ content. If a page is missing headings or they are empty or too long or vague, the search engine may find it difficult to match the page to particular search intent. Although such hiccups won’t harm indexing, they can undermine your pages’ ranking potential.
5. Your Site Was Penalized by Google
A huge drop down in rankings or a dropout from the index can be caused by changes in Google’s algorithms (Panda, Penguin, Hummingbird, Pigeon, and others) or decisions made by Google’s search quality raters. Both algorithms and human reviewers can punish a website for violating Google’s marketing best practices with the following black hat SEO techniques:
- Cloaking—showing different content to users and to Google’s crawlers.
- Sneaky redirects—setting redirects to pages that mismatch in content.
- Hidden text—making part of a page’s content invisible to users.
- Keyword stuffing—inserting repeated phrases in headings, body text, and metadata.
- Content spam—auto-generating gibberish or scrapping someone else’s content.
- Structured data misuse—applying Schema markup to misleading content.
- Link spam—buying or selling links and participating in link schemes.
- User-generated spam—allowing users to leave unmoderated comments with links.
- Dangerous, harassing, hateful, or other content doesn’t match Google’s policies.
If you suspect that your site got a penalty from Google, you should first check the Manual Actions section in Google Search Console. It’s unlikely for you to get a ban unless you’re implementing black hat SEO practices at scale. So, most likely, you’ll see a green tick and the ‘No issues detected’ message:

Still, if your website suddenly lost its positions in the SERPs, chances are an algorithm downgraded it. In this case, you won’t receive any messages in Google Search Console because the requirements of a particular algorithm got stricter, and your website no longer meets them.
You should avoid SEO malpractices by all means because recovering from Google’s penalties and algorithmic downgrades is a hard challenge. In some cases, manual actions can be revoked after bringing your content in line with Google policies and sending a reconsideration request. But it’s much harder to recover from the algorithm, as you’ll have to guess what you should do to get back on track and can’t send any requests to Google.
Final Words
We’ve gone through the main five issues that can prevent your website from indexing and ranking on Google. Most of them stem from technical issues and lie in the area of technical SEO. How do you cope with these issues?
First of all, you should find a tool that will help you keep track of your website’s technical health and spot problems on time.
With SE Ranking’s Website Audit, you’ll have scheduled website checks running automatically and generating comprehensive reports for you. None of the 110 potential issues checked by the tool will ever get past you – forewarned is forearmed.